
本教程只记录安装配置过程
- 先准备三台物理机
- 三台机安装同一版本的Proxmox [本教程版本为5.3.5]
- 如果是单硬盘需要在安装PVE时,把硬盘分区,第一分区只用20G,只供PVE系统自用,其余全部留给Ceph;如果是多块硬盘就自行分区吧。
- 网段定义为 192.168.5.0/24
Node1 192.168.5.101
Node2 192.168.5.102
Node3 192.168.5.103 - 三台机安装PVE后ssh进去,先升级PVE到最新版本
# vi /etc/apt/sources.list.d/pve-enterprise.list 把第一行注释掉
# vi /etc/apt/sources.list 内容清空后贴上以下内容
deb http://ftp.debian.org/debian stretch main contrib
deb http://ftp.debian.org/debian stretch-updates main contrib
deb http://ftp.hk.debian.org/debian stretch main contrib
deb http://download.proxmox.com/debian/pve stretch pve-no-subscription
deb http://ftp.hk.debian.org/debian stretch-updates main contrib
# security updates
deb http://security.debian.org stretch/updates main contrib
- 最后执行 apt update && apt dist-upgrade
前期准备工作完成,开始配置Cluster
一、先修改各节点机的 hosts 文件,目的是能用机器名称互访,而不是用IP地址。
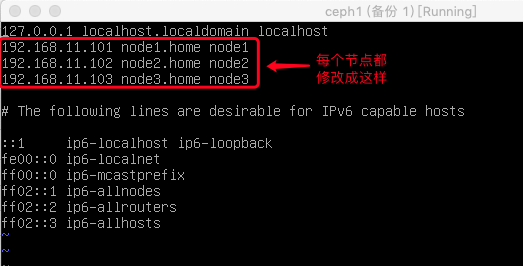
二 各节点配置第二网卡,网段为10.10.10.0/24 供Ceph储存网络使用,注意配置PVE的网络需要重启一下才生效
三 在每个节点上安装 Ceph
# pveceph install 或者 后面加上版本名称,例如:
# pveceph install –version luminous
安装后执行 (只需在任一节点上执行)
# pveceph init –network 10.10.10.0/24
在每个节点上安装Ceph Monitor
# pveceph createmon
然后在GUI界面为每个节点上用各自的第二块硬盘创建 Ceph OSD

接着创建 Ceph 储存池,大概理解就是把以上三台机的OSD建成一个共享储存分区吧

至此 Ceph 安装完成
配置HA高可用
在GUI –> 数据中心 –> HA –> 群组 把所有节点选择加入

在GUI –> 数据中心 –> HA 加入需要做HA的VM,群组使用需要的Ceph-pool 加入

最后请在各节点上安装ntp服务apt install ntp ,因为集群对时间的敏感度非常高,也可以使用内网的对时服务器。
日常维护:
A. 当某一节点PVE系统出现问题,需要重建该节点时,从其他任一节点进入系统,执行以下操作。
从集群中删除故障ceph
1.登录集群任意物理正常节点系统,执行如下命令查看ceph osd状态: ceph osd tree
2.离线有问题的ceph osd,执行的操作如下 ceph osd out osd.X X 代表 osd数字
3.删除已经离线osd认证信息,执行的操作如下: ceph auth del osd.X
4.彻底删除故障osd,操作如下:ceph osd rm X
5.查看集群osd状态,操作如下: ceph osd tree
6.删除故障节点的ceph磁盘,操作如下: ceph osd crush rm osd.X
7.从ceph集群中删除物理节点,操作如下 ceph osd crush rm pvename
8.然后从集群删除故障节点,操作如下 pvecm delnode pvename
最后编辑 /etc/pve/ceph.conf 删除故障 监视器配置 或者使用
ceph mon rm pvename 即可
等系统重新做好 加入集群即可
B. 当需要把原来有OSD分区的硬盘重新格式化加入到OSD时
使用 wipefs -af /dev/sdx 命令把硬盘擦写一次,然后要重启PVE系统OSD才能正常擦除或加入。 C. 集群迁移虚拟时ssh key出错问题,搞不清楚因什么原因导致的
错误信息:
task started by HA resource agent
2019-03-02 12:31:16 # /usr/bin/ssh -e none -o 'BatchMode=yes' -o 'HostKeyAlias=node19' [email protected] /bin/true
2019-03-02 12:31:16 @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
2019-03-02 12:31:16 @ WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED! @
2019-03-02 12:31:16 @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
2019-03-02 12:31:16 IT IS POSSIBLE THAT SOMEONE IS DOING SOMETHING NASTY!
2019-03-02 12:31:16 Someone could be eavesdropping on you right now (man-in-the-middle attack)!
2019-03-02 12:31:16 It is also possible that a host key has just been changed.
2019-03-02 12:31:16 The fingerprint for the RSA key sent by the remote host is
2019-03-02 12:31:16 SHA256:HGJz17oiOEKfdsklj437bfdjklasjfdsfjdisGfepL5IFFbDdWkec.
2019-03-02 12:31:16 Please contact your system administrator.
2019-03-02 12:31:16 Add correct host key in /root/.ssh/known_hosts to get rid of this message.
2019-03-02 12:31:16 Offending RSA key in /etc/ssh/ssh_known_hosts:1
2019-03-02 12:31:16 remove with:
2019-03-02 12:31:16 ssh-keygen -f "/etc/ssh/ssh_known_hosts" -R "node19"
2019-03-02 12:31:16 RSA host key for node19 has changed and you have requested strict checking.
2019-03-02 12:31:16 Host key verification failed.
2019-03-02 12:31:16 ERROR: migration aborted (duration 00:00:00): Can't connect to destination address using public key
TASK ERROR: migration aborted
官方解决方法:
ssh到迁移的目标主机上执行
vi /root/.ssh/known_hosts 把第一行删除,如果没有这个文件的话可以跳过这步
pvecm add 192.168.18.10 -force 这里的IP指向原集群第一台创建的节点IP地址,代表重新加入该集群,这样会重新生成key的。
然后再迁移就正常了.
D. mds报slow错误
(mds.0): 4 slow metadata IOs are blocked > 30 secs, oldest blocked for 73 secs
Ceph Health状态一直WARN,Ceph OSDs和PGs无任何问题或者报错一直Active+clean
解决方法:
打开感叹号看详细的报错信息,把相关节点的虚拟机先迁移到其他节点上,然后重启该节点即点。
E: 快照无法删除
错误:TASK ERROR: rbd error: error setting snapshot context: (2) No such file or directory
解决:
1)关闭该虚拟机
2)如锁了虚拟,使用 qm unlock vmid 解锁
3)进入 /etc/pve/qemu-server/ , 编辑 vmid.conf把快照名称里的配置内容全部删除。
F: 更换损坏的OSD硬盘
先找出坏硬盘:GUI –> Ceph –> 日志 找出损坏硬盘的盘符 /dev/sdx
然后 lsblk 命令和 ll /var/lib/ceph/osd/ceph-*/block 找出对应的OSD.x
root@kk:~# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sda 8:0 0 465.8G 0 disk
├─sda1 8:1 0 1007K 0 part
├─sda2 8:2 0 512M 0 part
└─sda3 8:3 0 464.7G 0 part
├─pve-swap 253:1 0 8G 0 lvm [SWAP]
├─pve-root 253:2 0 50G 0 lvm /
├─pve-data_tmeta 253:3 0 3.9G 0 lvm
│ └─pve-data 253:5 0 382.9G 0 lvm
└─pve-data_tdata 253:4 0 382.9G 0 lvm
└─pve-data 253:5 0 382.9G 0 lvm
sdb 8:16 0 1.8T 0 disk
└─ceph–c97694aa–6f13–4c2f–a786–28ebac862922-osd–block–9bb89567–986b–4525–8dca–4f00fbf619cb 253:7 0 1.8T 0 lvm
sdc 8:32 0 1.8T 0 disk
└─ceph–8334ceeb–5607–4b27–ab78–d8826ce67038-osd–block–0ff4a9e0–61e9–4e3e–801a–624efdb90407 253:0 0 1.8T 0 lvm
sdd 8:48 0 1.8T 0 disk
└─ceph–d6bdb8eb–4e14–47da–8ec4–c4690d821983-osd–block–75bcd156–d4b0–44d0–9a0e–e4ead6ca9e27 253:6 0 1.8T 0 lvm
sr0 11:0 1 1024M 0 rom
rbd0 252:0 0 5G 0 disk
rbd1 252:16 0 50G 0 disk
rbd2 252:32 0 50G 0 disk
rbd3 252:48 0 20G 0 disk
root@kk:~# ll /var/lib/ceph/osd/ceph-*/block
lrwxrwxrwx 1 ceph ceph 93 Aug 16 10:57 /var/lib/ceph/osd/ceph-4/block -> /dev/ceph-d6bdb8eb-4e14-47da-8ec4-c4690d821983/osd-block-75bcd156-d4b0-44d0-9a0e-e4ead6ca9e27
lrwxrwxrwx 1 ceph ceph 93 Aug 16 11:19 /var/lib/ceph/osd/ceph-5/block -> /dev/ceph-c97694aa-6f13-4c2f-a786-28ebac862922/osd-block-9bb89567-986b-4525-8dca-4f00fbf619cb
lrwxrwxrwx 1 ceph ceph 93 Aug 16 10:55 /var/lib/ceph/osd/ceph-6/block -> /dev/ceph-8334ceeb-5607-4b27-ab78-d8826ce67038/osd-block-0ff4a9e0-61e9-4e3e-801a-624efdb90407
1. 在ceph中删除损坏的硬盘
# 在monitor上操作
ceph osd out osd.5
# 在相应的节点机上停止服务
ceph stop ceph-osd@5
# 在monitor上操作
ceph osd crush remove osd.5
ceph auth del osd.5
ceph osd rm osd.5
2. 卸载硬盘
umount /var/lib/ceph/osd/ceph-5
3. 物理机关机更换硬盘,把新硬盘加入OSD pool里。
开机进入GUI控制台 --> 点选新硬盘所在的节点 --> 磁盘 -->
选中新硬盘并擦除硬盘(不要『使用GPT初始化磁盘』)--> Ceph --> OSD
--> 创建OSD --> 选择新硬盘创建即可
之后Ceph就会经历一段很长的时候做平衡和回填数据,直至Ceph状态恢复到健康。
Ceph 集群标志及维护说明
noup:OSD启动时,会将自己在MON上标识为UP状态,设置该标志位,则OSD不会被自动标识为up状态。
nodown:OSD停止时,MON会将OSD标识为down状态,设置该标志位,则MON不会将停止的OSD标识为down状态,设置noup和nodown可以防止网络抖动。
noout:设置该标志位,则mon不会从crush映射中删除任何OSD。对OSD作维护时,可设置该标志位,以防止CRUSH在OSD停止时自动重平衡数据。OSD重新启动时,需要清除该flag。
noin:设置该标志位,可以防止数据被自动分配到OSD上。
norecover:设置该flag,禁止任何集群恢复操作。在执行维护和停机时,可设置该flag。
nobackfill:禁止数据回填。
noscrub:禁止清理操作。清理PG会在短期内影响OSD的操作。在低带宽集群中,清理期间如果OSD的速度过慢,则会被标记为down。可以该标记来防止这种情况发生。
nodeep-scrub:禁止深度清理。
norebalance:禁止重平衡数据。在执行集群维护或者停机时,可以使用该flag。
pause:设置该标志位,则集群停止读写,但不影响osd自检。
full:标记集群已满,将拒绝任何数据写入,但可读
如何进行Ceph集群维护/关闭?
以下总结了关闭Ceph集群进行维护所需的步骤。
1、停止客户端使用您的群集(仅当您要关闭整个群集时才需要执行此步骤)
重要提示:在继续操作之前,请确保群集处于健康状态。
现在,您必须设置一些OSD标志:
# ceph osd set noout
# ceph osd set nobackfill
# ceph osd set norecover
这些标志应该足以安全关闭集群电源,但是如果您想完全暂停集群,也可以在顶部设置以下标志:
# ceph osd set norebalance
# ceph osd set nodown
# ceph osd set pause
暂停群集意味着您看不到OSD何时出现。再次备份,不会发生地图更新。
2、关闭您的服务节点
3、关闭您的OSD节点
4、关闭您的监视器节点
5、关闭您的管理节点
维护后,以相反的顺序进行上述所有操作。
完全删除Ceph集群
1. 停止Ceph服务:
#systemctl stop ceph.target
2. 卸载Ceph软件包:
#apt-get remove ceph-common ceph-mon ceph-osd
3. 删除Ceph配置文件:
#rm -rf /etc/ceph
4. 删除Ceph数据和日志文件:
#rm -rf /var/lib/ceph/osd 删除OSD数据
#rm -rf /var/lib/ceph/mon 删除MON数据
#rm -rf /etc/systemd/system/ceph*.service
#rm -rf /var/run/ceph
重启系统确保所有Ceph相关服务和进程都已停止。
最后删除Ceph相关目录和文件:
#rm -rf /etc/ceph/*
#rm -rf /var/lib/ceph/*
#rm -rf /var/log/ceph/*
#rm -rf /var/run/ceph/*
全部命令行:
systemctl stop ceph-mon.target
systemctl stop ceph-mgr.target
systemctl stop ceph-mds.target
systemctl stop ceph-osd.target
rm -rf /etc/systemd/system/ceph*
killall -9 ceph-mon ceph-mgr ceph-mds
rm -rf /var/lib/ceph/mon/ /var/lib/ceph/mgr/ /var/lib/ceph/mds/
pveceph purge
apt purge ceph-mon ceph-osd ceph-mgr ceph-mds
apt purge ceph-base ceph-mgr-modules-core
apt autoremove
apt autoclean
rm -rf /etc/ceph/*
rm -rf /etc/pve/ceph.conf
rm -rf /etc/pve/priv/ceph.*